
お久しぶりです、グッチです。
最近5000兆円を手に入れました。
目が覚めたら無くなりました。

バックエンド
エンジニア
グッチ
はじめに
ある日急に集計を依頼されたものの、元のデータがフリーテキストで困ったエンジニアの話をします。
ロジカルスタジオでは独自の日報システムを使用しています。
その日報を入力する際、作業種別をプルダウンから選ぶようになっています。
ある程度の種別を用意しているものの、どうしても「その他」という選択肢も必要になります。
「その他」の内容として入力されたフリーテキストから、
どういった内容が「その他」として登録されているのか集計する
というのが目的になります。
フリーテキストなので助詞や接続詞などで表記が揺れて集計しずらい為、
NLPライブラリを利用して集計しやすいようにします。
茶番
ある日ー…
(入社して1年かぁー、仕事も慣れてきてヒマになったなー)
バックエンド
エンジニア
グッチ
グッチ君

エンジニア
リーダー
本谷さん
は、はい!なんでしょう真面目に仕事しとりますが。
今年新卒で入社した子たちの稼働について報告しないといけないんだけど、
マカロン(日報システムの名前)のデータから集計して貰えるかな。
1週間後で良いよ。
1週間後ですか?あー最近ちょっと忙しくしてまして。。
あ!あすにゃん!あすにゃんが時間空いとりますので彼女に

バックエンド
エンジニア
あすにゃん
(あんた暇そうにしとったやろ。。)
そうだね。。
グッチ君だけだと不安があるので、あすにゃんサポートお願い出来るかな?
はぁ、分かりました。
サポートだけで良いからね。
グッチ君、じゃあ1週間後によろしくね。
分かりました、何とかします!
(集計するだけやし一瞬で終わるやろ。。)
1週間後ー…
グッチさん、昨日も言いましたけど例の集計の件、明日が締め切りですよ?
(アカン、忘れとった)
あぁーアレね、大丈夫SQL一発で集計出来るから
(ほな早よしろ)
さすがですねー(棒)
じゃあもういい加減やりましょうか(真顔)
そ、そうやね。そろそろやろか。
マカロンのDBにつないで、っと(ゴソゴソ)
ユーザー毎に月単位で…(ゴソゴソ)
更に作業種別の作業時間を合計するだけ…(ゴソゴソ)
ほれ出来たで
んー…?ちょっと見せてくださいね
(いやー楽勝楽勝、鼻ほじってても出来るわ)
グッチさん、これマズいかもしれませんよ
ん?そんなわけあるかいな
クエリは間違って無いと思うで
クエリは正しいと思うんですが、「その他」の時間が大きすぎて、報告にするにはもう少し詳細取らないとダメなんじゃないかと
ホンマや。。(白目)
いやいや、これは本谷さんが「集計するだけで良い」って言ってたし条件は満たしとる。これで出すで
(クエリ流して合計するだけとは言ってないんだよなー。。)
本谷さんの席
本谷さん、例の集計の件出来ました。。
(恐る恐る)
ありがとう、ちょっと確認するので待っててください。
(チラッチラッ)
(いや絶対アカンやろ)
うん、この「その他」の割合が多いから、
その詳細まで見える報告にしないと不合格だね。(満面の笑顔)

(ですよねー)

いやー、そうやと思ってたんですけどねー!
あすにゃんがコレでイケる言いよるもんですから!
おい
でもこれー、似た業務内容でも個人によって書き方が違いますし、SQLで集計なんて。。
そうだね、表記揺れの排除は要るかもしれないね。Python得意って言ってなかったかな?
パイホン?
パイソンです。
じゃあ一旦データを抜き出して、ローカルで集計処理ですね。
そうなるね。
傾向が分れば良いだけなので、複雑な集計にはならないと思うよ。
グッチ君、出来るかな?
お任せください!
パイソンはあすにゃんが大得意です!

ええ加減にせい

STEP1:NLPライブラリの選択
さっそく「日本語 NLP ライブラリ」でgoogle検索しましょう。
GiNZA一択ですね。
公式を軽く読むとPythonの環境が要るらしい。
環境を作っていきましょう。
STEP2:Python環境を作る
茶番に書いたようにPython得意(笑)だったら良かったのですが、現実には1度触ったことが有るくらいです。
windows上でやるかdockerでやるか。
悩んだ結果dockerを選択しました。 (windowsの場合詰まった時に何が原因か分からんイメージが。。)
「python docker image」でgoogle検索します。
オフィシャルも良いですが、先人の知恵が詰まっていそうなので3つ目のqiitaの記事を参考にしました。
この方は「jupyterlab」を使いたかったようですが、この記述をGiNZAに変更します。
GiNZAの公式を見ると、セットアップは下記のコマンドで良いとの事。
pip install -U ginza https://github.com/megagonlabs/ginza/releases/download/latest/ja_ginza_electra-latest-with-model.tar.gzDockerfileはこうなります。
docker-compose.ymlは記事のままで良いでしょう。
FROM python:3
USER root
RUN apt-get update
RUN apt-get -y install locales && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
ENV TERM xterm
RUN apt-get install -y vim less
RUN pip install --upgrade pip
RUN pip install --upgrade setuptools
RUN pip install -U ginza "https://github.com/megagonlabs/ginza/releases/download/latest/ja_ginza_electra-latest-with-model.tar.gz"後は普通にdocker-composeでビルドします。
STEP3:抽出処理
pythonのコンテナに入り、~/optへ移動するとそこがマウントディレクトリになっています。
ここでスクリプトを組んでいきます。
今回やりたいのは、フリーテキストがずらっと並んだCSVに1行ずつNLPの処理をかまし、
助詞を取り除いた名詞句を抜き出して集計するという内容です。
元となるCSVはこんな内容。

1.GiNZAライブラリをインポート
2.CSVを読み込む
3.1行づつnlpをかます
という流れなので、GiNZA公式にある「Pythonコードによる解析処理の実行」という節の内容に従ってまずは1行だけ試してみます。
コードはこちら。
import spacy
nlp = spacy.load('ja_ginza_electra')
f = open('daily_report_details.csv', 'r')
datalist = f.readlines()
doc = nlp(datalist[0])
for sent in doc.sents:
for token in sent:
print(token.i, token.orth_, token.lemma_, token.pos_, token.tag_, token.dep_, token.head.i)
print('EOS')
f.close()さっそく実行しましょう。
root@7bc5aff4e1f3:~/opt# python aaaa.py
0 " " PUNCT 補助記号-一般 punct 2
1 # # SYM 補助記号-一般 compound 2
2 日報 日報 NOUN 名詞-普通名詞-一般 nmod 5
3 へ へ ADP 助詞-格助詞 case 2
4 通知 通知 NOUN 名詞-普通名詞-サ変可能 compound 5
5 テスト テスト NOUN 名詞-普通名詞-サ変可能 ROOT 5
6 " " PUNCT 補助記号-一般 punct 5
EOS
7
NOUN 空白 ROOT 7
EOSう~ん、10行目の第4引数の「token.pos_」というのがNOUNになってるものが抽出出来れば良さそうだけども。。
何というか細かく分かれ過ぎている気がします。
出来れば「通知テスト」みたいにまとまったワードが欲しい。
調べてみると、8行目のdoc.sentsの代わりにdoc.noun_chunksというのが使えるらしい。
試してみると、
root@7bc5aff4e1f3:~/opt# python aaaa.py
"#日報
通知テスト
これじゃぁ~~~!!!
得たい結果の出し方が分かったので、後はひたすらcsvを1行ずつ読んでnoun_chunksを吐き出していくだけです。
一応、実行前にcsvからダブルクォーテーションや・や#などの要らん記号は削除しておきましょう。
ソース内容はこうなりました。
import spacy
nlp = spacy.load('ja_ginza_electra')
f = open('daily_report_details.csv', 'r')
wf = open('result.txt', 'w')
datalist = f.readlines()
for dataline in datalist:
doc = nlp(dataline)
for np in doc.noun_chunks:
wf.write(str(np) + '\n')
f.close()
wf.close()で、実行しますが…

GPU使わんなぁ。。
公式にはCUDAを使用する方法が書いてありますが、会社のPCにCUDAなんか入ってないので仕方ないですね。
15,000行の処理をひたすら待ちます。
待つこと12分。
出力したテキストを小文字→大文字に変換した上でソートしExcelに貼り付けると、良い感じに同じ作業内容が並ぶ結果になりました。
弊社の社内雑務「その他」のTOP10までを発表します。
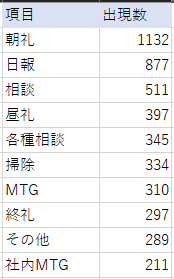
うーん納得の結果。
面白いのが、9位に「その他」が再出現している事。
これはもう分からんな。。
ま・と・め
・日本語NLPはGiNZAというライブラリが有名らしい
・GiNZA関係の記事を読むとnlp = spacy.load('ja_ginza')というサンプルが良く見つかるが、これは古いバージョンで下記のエラーが起きる。
現行バージョン(v5.x)ではnlp = spacy.load('ja_ginza_electra')
Can't find model 'ja_ginza'. It doesn't seem to be a shortcut link, a Python packageor a valid pathto a data directory・doc.noun_chunksで少しまとまった名詞句を取得できる
・ロジカルスタジオは朝礼の時間を削減するなど業務改革の必要がある
・ロジカルスタジオでは後輩に仕事を押し付けるとコロコロで殴られる
最後に
さて、弊社ロジカルスタジオでは種類を問わず様々な職種・技術で一緒に働ける方を募集しております。
採用サイトには会社の雰囲気や社員インタビューなど、たくさん情報が掲載されているのでお気軽に覗いてみてください!

